

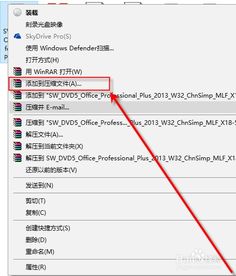
标签分割慢怎么办
标签打印软件提交打印机机打印的页数太多,处理太慢怎么办?
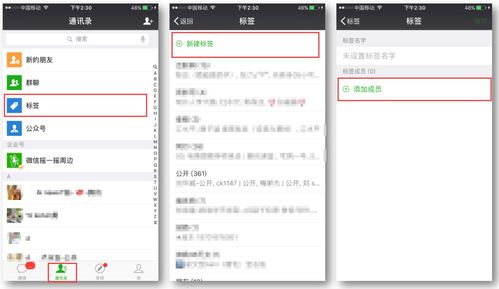 要是打印机处理慢的话,我用的这个中琅软件里面有一个拆分任务的功能,就是可以将1000页的任务,拆分成50页一个或者100页一个去提交打印机打印,这样打印机就不用一次性的处理1000张,会快很多
要是打印机处理慢的话,我用的这个中琅软件里面有一个拆分任务的功能,就是可以将1000页的任务,拆分成50页一个或者100页一个去提交打印机打印,这样打印机就不用一次性的处理1000张,会快很多为什么在火狐的标签页之间转换显得很慢,是怎么回事?有好的办法吗?
您好,感谢您对火狐的支持火狐在各标签页间切换应该是很快的,如果明显速度很慢,打开帮助---安全模式启动测试下,若恢复正常就是扩展出错造成的,为浏览器新建一个配置文件。您可以在火狐官方网站下载火狐浏览器,在火狐社区了解更多内容。
希望我的回答对您有所帮助,如有疑问,欢迎继续在本平台咨询。
小标签纸打印很慢是怎么回事?
 你说的时打印速度很慢吗,小标签纸应该是不会出现这种情况的,一般来说在标签打印的时候,只有调用很多矢量图或者提交的打印任务页数非常多的时候,才会打印比较慢,不过对于打印速度方面,一般都是在打印机里面设置的,或者你也可以用一个中琅的标签打印软件,这个软件里面在提交打印任务的时候有一个拆分任务的功能,就是如果你要一次性提交100页可能会比较慢,但是如果要一次提交10页,就处理的比较快了:还有如果你的标签背景要是矢量图的话,也可以用那个画布背景图的功能,这样就不用每个标签都调用一次矢量图,也会提速不少:
你说的时打印速度很慢吗,小标签纸应该是不会出现这种情况的,一般来说在标签打印的时候,只有调用很多矢量图或者提交的打印任务页数非常多的时候,才会打印比较慢,不过对于打印速度方面,一般都是在打印机里面设置的,或者你也可以用一个中琅的标签打印软件,这个软件里面在提交打印任务的时候有一个拆分任务的功能,就是如果你要一次性提交100页可能会比较慢,但是如果要一次提交10页,就处理的比较快了:还有如果你的标签背景要是矢量图的话,也可以用那个画布背景图的功能,这样就不用每个标签都调用一次矢量图,也会提速不少:为什么网页标签打开非常慢?
影响网页打开速度的因素主要有如下几方面: 1、用户和网站处于不同网段,例如电信用户与网通网站之间的访问,也会出现打开网页速度慢的问题。连接一个VPN代理服务器可以解决,推荐网一VPN,百度直接搜索网一VPN 就能找到。
2、系统有病毒,尤其是蠕虫类病毒,严重消耗系统资源,打不开页面,甚至死机。
3、本地网络速度太慢,过多台电脑共享上网,或共享上网用户中有大量下载时也会出现打开网页速度慢的问题。 4、使用的浏览器有BUG,例如多窗口浏览器的某些测试版也会出现打开网页速度慢的问题。 把你的本地网络重启一下,网络修复一下.360把IE修复一下,360卫士/高级/IE修复。 5、访问的网站负荷太重,带宽相对太窄,程序设计不合理,也会出现打开网页速度慢的问题。
6、网络防火墙的设置不允许多线程访问,例如目前WinXPSP2就对此默认做了限制,使用多线程下载工具就受到了极大限制,BT、迅雷都是如此。因此,同时打开过多页面也会出现打开网页速度慢的问题。 7、是否和系统漏洞有关,也不好说,冲击波等病毒就是通过漏洞传播并导致系统缓慢甚至瘫痪的 8、网络中间设备问题,线路老化、虚接、路由器故障等。
手持线缆标签打印机出纸慢是怎么回事?

一、打印机要预热均匀才能够打印 二、打印数据传输,查看打印线是否有问题; 三、驱动里面的打印首选项里面有个质量选项,有打印质量区分,一般打印质量越高,打印速度就越慢; 四、打印机有问题,可能是加热组件不好。 1.打印机(Printer) 是计算机的输出设备之一,用于将计算机处理结果打印在相关介质上。
2.衡量打印机好坏的指标有三项:打印分辨率,打印速度和噪声。
3. 打印机的种类很多,按打印元件对纸是否有击打动作,分击打式打印机与非击打式打印机。按打印字符结构,分全形字打印机和点阵字符打印机。按一行字在纸上形成的方式,分串式打印机与行式打印机。按所采用的技术,分柱形、球形、喷墨式、热敏式、激光式、静电式、磁式、发光二极管式等打印机。
用于语义分割的分层多尺度注意力
https://arxiv.org/abs/2005.10821 https://github.com/NVIDIA/semantic-segmentation 1.5k星 21 May 2020 最近开源了: https://paperswithcode.com/paper/hierarchical-multi-scale-attention-for#code 摘要: 多尺度推理常用于改善语义分割结果。将图像缩放到多个不同尺度,再输入给同一个网络,再将结果取平均或最大池化。
本文提出一个基于注意力的方法来组合多尺度预测。
我们表明,某些尺度下的预测更能处理特定的故障情况,而网络学会了在这种特定情况下更倾向于这些尺度,以便输出更好的结果。我们的注意力机制是分层的,这使得它的内存效率比其他最近的方法快4倍。这样除了能够训练地更快以外,还能让我们使用更大的裁剪尺寸训练,从而使得模型准确度更高。我们在Cityscapes和Mapillary Vistas两个数据集上验证我们的方法。
对于具有大量弱标注图像的Cityscapes数据集,我们还利用自动标注改进泛化能力。我们的方法在Cityscapes数据集(85.1 IOU test)和Mapillary Vistas数据集(61.1 IOU val)上都取得最先进水平。 关键词:语义分割、注意力、自动标注 1.引言 语义分割的任务是给图像中所有像素打上多个类别中的一个的标签。
该任务有个折中,就是某些情况下的预测在低分辨率下推理得更好,而另一些情况下的预测在高分辨率下推理得更好。在放大的图像尺寸下,精细的细节,例如物体边缘或者细长的结构,会推理得更好。同时,缩小的图像尺寸下,对需要更多的全局上下文信息的大物体会推理得更好,因为网络的感受野可以观察到更多的必要的上下文信息。
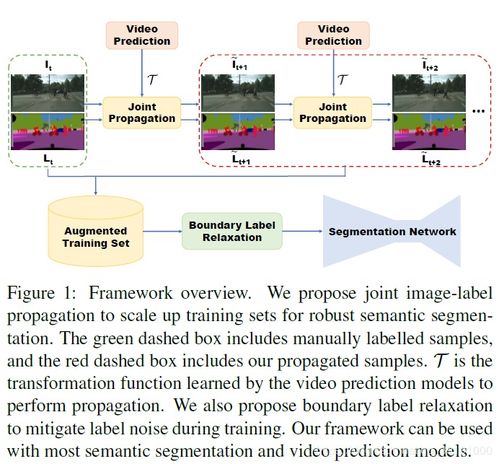
我们将后一种问题称为类别混淆(class confusion)。两种情况的例子如图1所示。 多尺度推理是这一问题的常见解决办法。
图像缩放到多个不同尺度,再输入给同一个网络,再将结果取平均或最大池化。取平均来组合多个尺度的预测通常可提高结果,但存在将最佳预测和最差预测结合的问题。煮个栗子,对于某像素,最佳预测来自2×尺度,其0.5×尺度的预测要差很多,取平均的话会将这两者结合起来,得到一个次优的输出。另一方面,最大池化是选择该像素在多个尺度预测中的一个,而最优结果可能是多个尺度预测的加权组合。
为了解决这个问题,我们提出一种使用注意力机制来将某像素的多个尺度预测结合在一起的办法,类似于Chen[1]。我们提出一种层次化的注意力机制,学习预测相邻尺度之间的关系权重,由于它是层次化的,所以我们只需要增加一个额外的尺度的训练pipeline,而其它的方法,例如[1],则需要在训练阶段显示地增加每一个额外的推理尺度。例如,当多尺度推理为{0.5,1.0,2.0}时,其它的注意力方法要求网络在所有这些尺度上训练,导致额外的 倍的训练成本。我们的方法只需要再增加0.5×尺度的训练,导致增加 倍的训练成本。
此外,我们提出的层次化机制还可使推理时具有选择额外的尺度的灵活性,而以往的方法在推理的时候只能使用训练时候的尺度。为了在Cityscapes上取得最先进水平,我们还使用了一种对粗标注图像的自动标注策略,以增加数据集中的方差,以提高泛化能力。我们的自标注方法是受一些最近的工作的启发,包括[2,3,4]。和典型的软标签不同,我们使用硬标注,这样标签存储内存就更小,可以降低磁盘IO成本,提高训练速度。
1.1 贡献 一种高效地层次化注意力机制,使网络可以学习如何最好地组合多个尺度的推理,能解决类别混淆和细节的问题。 一种基于硬-阈值的自动标注策略,利用未标记图像来提升IOU。 在Cityscapes数据集(85.1 IOU test)和Mapillary Vistas数据集(61.1 IOU val)上取得最先进水平。
2 相关工作 多尺度上下文 最先进的语义分割网络使用低输出步长的主干网络,这可以更好地分割细节,但是感受野也较小。小的感受野会导致网络难以预测大物体。金字塔池化可通过组合多个尺度的上下文来解决感受野较小的问题。
PSPNet[5]使用一个空间金字塔池化模块,使用主干网络的最后一层的特征,用一些列卷积和池化来组合多个尺度的特征。DeepLab[6]使用Atrous Spatial Pyramid Pooling(ASPP),用不同扩张率的扩张卷积,以建立比PSPNet更加稠密的特征。最近ZigZagNet[7]和ACNet[8]使用中间层特征,而不仅仅是最后层特征,来创建多尺度上下文。 关系上下文 实际上金字塔池化关注的是固定的方形上下文区域,因为池化和扩张通常都是对称的。
此外这些方法是固定的,不是可学习的。关系上下文通过关注像素之间的关系来构建上下文,而不是固定的方向区域。关系上下文的可学习特性使得上下文的构建可基于图像的各个分区。
该方法能够对非正方形的物体区域构建更合适的上下文,例如长火车和细高的灯柱。OCRNet[9]、DANET[10]、CFNet[11]、OCNet[12]和其他相关工作[13,14,15,16,17,18,19,20]利用这些关系来构建更好的上下文。 多尺度推理 一些关系上下文和多尺度上下文方法都使用了多尺度推理来达到最好的结果,例如[21,22,23,9]。多尺度推理有两种常见方法:取平均和最大池化,取平均要更常见些。
然而,取平均对不同尺度的输出是等权重的,这样的结果可能是次优的。为了解决这个问题,[1,24]使用注意力组合多个尺度。[1]使用网络的最后层特征来训练一个建模各个尺度间关系的注意力头。
[24]组合不同层的特征来构建更好的上下文信息。然而,这两种方法有共同的确定,网络和注意�。


免责声明:本站部分内容由用户自行上传,如权利人发现存在误传其作品,请及时与本站联系。
冀ICP备18013120号-1